|
Freeware program
Decision tree with Time limit
|
 |
 |
Дерево принятия решений - один из мощных средств для анализа больших данных. Деревья предназначены для задач классификации. И с этим справляются иногда лучше, чем нейросети. Подробнее тут или тут
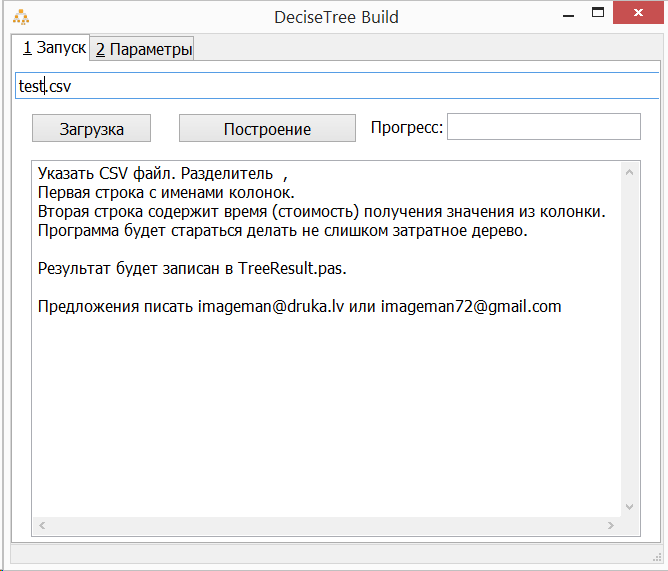
Программа "Дерево решений с ограничением по времени" дает возможность создать (обучить) такое дерево на основе данных из CSV файла. Что такое "с ограничением по времени"? Очень часто получение каких-то параметров более затратное, стоит больше. Яркий пример - постановка медицинского диагноза. Врач (по сути) имеет дерево решений в своей голове. Он начинает опрос с более простых вопросов, которые можно быстро получить (мало затрачивается времени). И только в случае проблем с диагностикой на более поздних стадиях обследования назначаются анализы. Начинают с более быстрых-дешевых. Подобная ситуация возникает и в других случаях. Например при анализе фотографий какие-то характеристики считаются очень быстро и именно с них нужно начинать анализ.
Программа написана на языке Delphi, можно скачать 32-битную версию. Результат программы в виде Pascal кода, который может быть легко адаптирован под любые универсальные языки программирования (php, C++, C#, JavaScript и т.п.).
Входной файл для программы должен быть в текстовом виде. Для задачи из Википедии первые строки CSV файла могут быть:
Sopernik, Igra, Lider, Dozdik, Result
1 , 1 , 1 , 1 , 1
1,1,1,1,0
1,1,1,0,1
1,1,0,0,0
0,1,0,0,1
0,0,0,0,0
0,1,0,1,1
1,0,1,1,0
Первая строка дает имена переменным, вторая строка для всех переменных указывает стоимость 1, дальше сами данные. Поскольку программа оптимизирована на большее число строк, то параметр MinTreeRecords не может быть неньше 6. Поэтому мы 3 раза размножаем наши входные данные.
Результат программы (вручную отформатированный):
{Time 3.36363636363636}
{ число правильных 19 of 22, процент правильных 0.863636363636364 }
{Time 2, count 1.000, mean 0.409, entropy 0.677 range 0 .. 1 }
if (Sopernik*Dozdik<1) then
begin
{Time 2, count 0.682, mean 0.6, entropy 0.673 range 0 .. 1 }
if (Lider+Dozdik<1) then
Result:=0
else
Result:=1
end
else
Result:=0
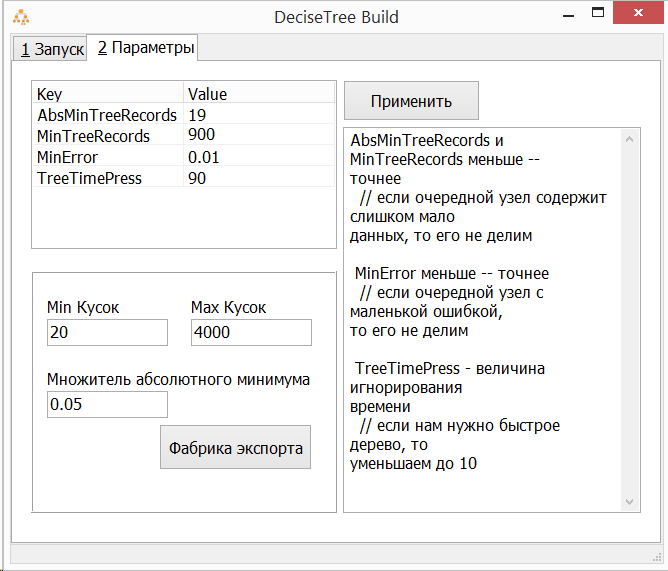
{ AbsMinTreeRecords=1; MinTreeRecords=6; MinError=0.01; TreeTimePress=90 EdgePenalty=0 }
Результат сохраняется в текущую директорию с именем TreeResult.pas.
Time 3.36 означает, что в среднем на решение одной строки тратится 3,36 единицы времени.
{Time 2, count 1.000, mean 0.409, entropy 0.677 range 0 .. 1 }
if (Sopernik*Dozdik<1) then
Time 2 - означает, что стоимость условия "if (Sopernik*Dozdik<1) then" равна 2.
count 1.000 - в среднем это условие срабатывает в 100% всех случаев.
mean 0.409 - среднее значение результирующей колонки ДО условия равно 0,409
entropy 0.677 - среднее значение энтропии результирующей колонки ДО условия 0,677 (чем меньше это значение, тем "упорядоченнее" данные до этого условия).
range 0 .. 1 - в каком диапазоне изменяется переменная Sopernik*Dozdik в этом условии. На некоторые вопросы можно получить ответы на странице "Вопросы и ответы".
В бесплатной версии:
- 64-битность;
- пропущены некоторые проверки.
Программа тестировалась на 1,5 миллионах строк (60 колонок). Время построения 5 минут (Deep=-1), размер TreeResult.pas от 15 до 40 kb (в зависимости от настроек).
Требования к данным
Информация об объектах, которые необходимо классифицировать, должна быть представлена в виде конечного набора признаков (колонок), каждый из которых имеет числовое значение. Такой набор атрибутов назовём примером (строка). Для всех примеров количество колонок и их состав должны быть постоянными. Множество классов, на которые будут разбиваться примеры, должно иметь конечное число элементов, а каждый пример должен однозначно относиться к конкретному классу. Число классов не более 256 (нумерация от 0 до 255). Для случаев с нечёткой логикой, когда примеры принадлежат к классу с некоторой вероятностью, программа неприменима. В обучающей выборке количество примеров должно быть значительно больше количества классов, к тому же каждый пример должен быть заранее ассоциирован со своим классом.
|
Загрузить Decision_Tree.7z (1390kb); Decision_tree_1.7beta.7z (1390kb); pad file |
05-янв-2019 v 1.7 бэта Реализовано кэширование результатов построения. За счет этого при благоприятных условиях ускорение повторного построения дерева в 2-3 раза.
06-ноя-2017 v 1.5 Добавлена частичная мультипоточность (ускорение вычислений).
Эксперименты с множественной линейной регрессией.
"Фабрика экспорта" предназначена для подбора таких параметров, которые минимизируют ошибку при тестировании.
Ошибка при тестировании вычисляется чуть по другому (вычисляется процент правильных для каждого класса, после этого вычисляется среднее между ними).
Исправлена ошибка выделения памяти.
25-апр-2015 v 1.02 Исправлена неправильная работа при Deep 3 и 4.
23-апр-2015 v 1.01 Добавлено автоматическое исследование комбинаций колонок (Deep=1 попарное умножение, Deep=2 сложение, Deep 3 и 4 добавляет ещё одно умножение/сложение).
12-апр-2015 v 1.00 Базовая функциональность.