|
DecisionTreeBuilder: Вопросы и ответы
|
 |
 |
Что программа делает?
Программа позволяет построить на основе обучающих данных классификатор. Встроив этот классификатор в свою программу вы получите возможность классифицировать новые данные. Условно говоря узнавать "здоров-болен" или "полетит-не полетит".
А что, возможно только два класса?
Нет. Число классов в этой версии может быть 256 (классы пронумерованы от 0 до 255).
А классы обязательно нумеровать? Может можно оставить словесное описание (например "синий", "зеленый", "черный")?
Все входные данные должны быть в виде чисел. Если вам нужно работать с категориальными признаками, то вам их нужно превратить в числа (подробнее).
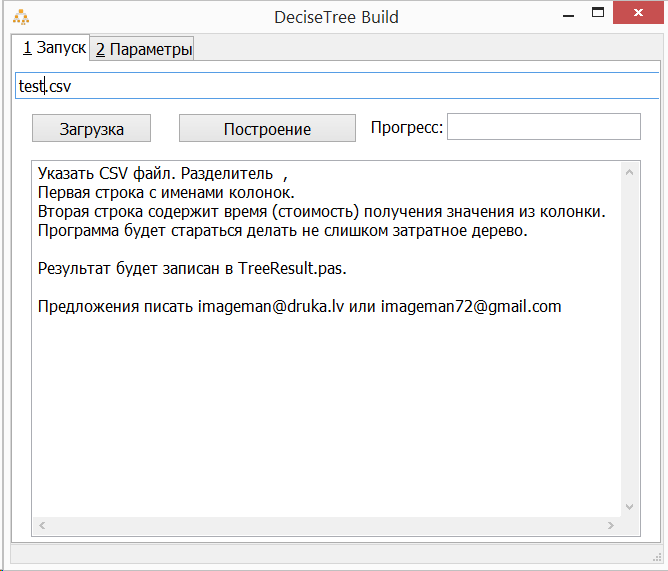
Как мне выбрать какие данные из csv файла для обучения, а какие данные отвечают за ответ?
В программе жестко прописано, то первая строка описывает колонки в виде
input1, input2, input3, Result
(при этом можно использовать спецсимволы, например "A+B" или "A[555]")
Вторая строка отвечает за "стоимость" использования каждого параметра. Например
input1, input2, input3, Result
1, 50, 100,1
Укажет, что input1 использовать "дешевле", чем input2 и, тем более, input3. Поэтому в дереве решения input1 будет чаще мелькать (многое зависит от данных). Эту строку можно просто заполнить 1,1,1,1
Далее следуют сами обучающие данные.
Программа будет использовать все колонки. Последняя колонка считается результатом (категорией). Все числа (кроме категории) могут быть дробными.Что это за чекбокс "DAT"?
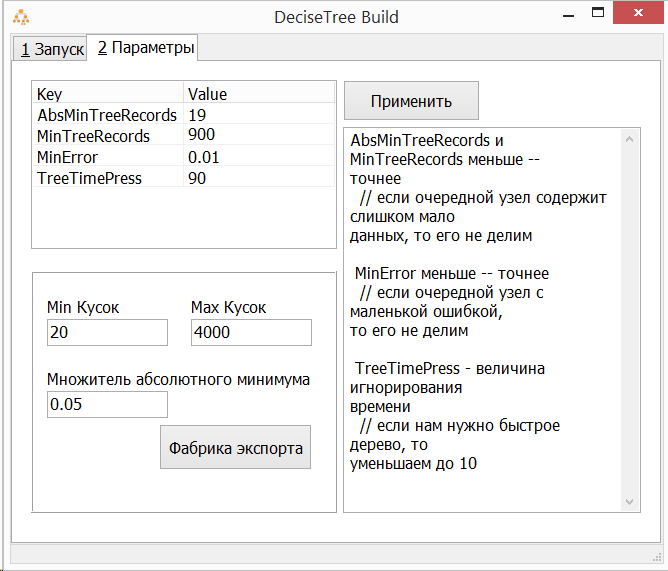
Для ускорения загрузки данных при построении леса деревьев программа может конвертировать текстовый csv файл в бинарный dat. При изменении даты модификации csv файла dat файл будет автоматически перестроен.
Что это за чекбокс "Cached"?
Во время разработки зачастую требуется строить дерево решений сотни раз. Кэширование промежуточных результатов построения дерева решений позволяет ускорить работу в 2 и более раз. При включенном кэшировании не выполняется полный перебор колонок в случае, если в кэше уже имеется нужный ответ (выполняется только подбор порога одной единственной колонки). Именно поэтому чем больше колонок в нашем csv файле, тем эффективнее работает кэширование.
А почему у меня кэширование не работает?
Для эффективной работы технологии кэшироания нужно: а) число колонок больше 10; б) число запусков построения более 50 (для "прогрева" кэша); в) достаточно большое количество обучающих данных (более 10 000). Если одно из условий не выполняется, то кэширование не принесет существенного ускорения.
На каких языках программирования можно использовать эти классификаторы?
Существенных ограничений нет. Это может быть Java, Javascript, C#, C++, C, PHP, Delphi, Pascal и т.д. Дело в том, что результат это текстовый файл вида "if (условие) then действие_1 else действие_2". Путем запуска в текстовом редакторе ряда Find-Replace (Найти и заменить) можно адаптировать полученное дерево к большинству универсальных языков программирования.
А как-то автоматически можно встроить дерево в мою программу?
Можно написать bat файл (скрипт) который будет это делать автоматически. Правда для этого ещё нужна программа, которая умеет делать из командной строки поиск и замену в файлах. Например Text Replacer, Sed, или вот эта программа. Можно найти программу на свой вкус. Преобразованный файл можно легко использовать в вашей программе (обычно достаточно прочитать справку по параметру "include" вашего языка программирования).
Какая точность у программы?
Сама программа работает с дробными числами одинарной точности (для уменьшения потребления памяти), но в большинстве случаев это никак не влияет на точность полученного дерева решений. Гораздо больше зависит от самих данных. Общее правило: чем больше данных и чем они полнее, тем лучше классификатор. Так же не забывайте о правиле: "Мусор на входе - мусор на выходе". В целом дерево решений зачастую дает точность сопоставимую с нейронными сетями, но обучается и работает при этом, как правило, намного быстрее.
Можно ли увеличить точность?
Да, есть несколько способов сделать результаты точнее. Самый известный способ - построение леса деревьев (подробнее про лес искать тут). Так же следует обратить внимание, что программа выдает классификацию в виде "begin Result:=0{p:=0.925} end". Т.е. класс скорее всего будет "0". Здесь p:=0.925 означает, что дерево уверено в результате на 92.5%. (Если дерево уверено на 100%, не обольщайтесь - это всего лишь прогноз.) Информацию об уверенности в результате можно использовать при построении комитета деревьев.
Как при помощи DecisionTreeBuilder построить лес деревьев?
Напрямую возможность построения не реализовано. На данный момент можно поступить так: открываем программу, настраиваем параметры построения как нужно. Ставим ползунок "Тестовый набор" (под кнопкой "Загрузка") в положение 40% и создаем дерево решений. В этом случае для построения будет использовано только случайных 60% всех данных. После этого делаем build.bat файл с примерно таким содержанием:
start /wait /low /min DecisionTreeBuilder.exe /autostart
start /wait /low /min DecisionTreeBuilder.exe /autostart
start /wait /low /min DecisionTreeBuilder.exe /autostart
Параметр /autostart означает, что нужно приступить к построению дерева решения немедленно и использовать для этого последние настройки. После построения DecisionTreeBuilder автоматически закроется. В директории с результатами можно будет найти множество файлов TreeResult.pasXXX.bak (где XXX числа от 1 до 340), которые будут немного отличатся, потому что обучающие данные при каждом запуске будут немного отличатся.
Я получаю ошибку "Out of memory", хотя на компьютере много памяти. Можно ли что-то сделать?
Видимо у вас слишком много данных и превышен порог в 2 гигабайта. Дело в том, что бесплатная версия 32-битная, а эти программы имеют существенно ограничение на размер одновременно обрабатываемых данных. Нужно связаться со мной (imageman72@gmail.com) что бы обсудить возможные варианты решения.
Какая скорость построения дерева решений?
Скорость очень большая. Время построения обычно от десятка секунд до нескольких минут. На моих данных (число столбцов 1429, число строк 501199, что составляет 716 миллионов чисел - примерно 3 Гб двоичных данных при использовании 64-битной версии программы) время построения с использованием кэша 4 минуты, без использования кэша 12 минут (Intel core i5-4690S 3.2 GHz, RAM 16 Gb).